元素选择器
元素选择器是九头虫 RPA 中定位页面元素的核心工具。几乎所有需要操作 DOM 的节点都依赖选择器来指定目标。
九头虫 RPA 提供 两种元素定位方式:
- AI 自然语言选择器:用大白话描述你想要什么元素,AI 自动帮你找到并生成 CSS 选择器。零基础也能立刻上手。
- CSS 选择器:在浏览器原生 CSS 选择器基础上,扩展了 8 个自定义伪类,覆盖 Shadow DOM 穿透、文本匹配、表格列定位、视口过滤等自动化高频场景。
AI 自然语言选择器(推荐新手使用)
不知道该写什么 CSS 选择器?直接告诉 AI 你想要什么。输入一句自然语言描述,AI 会分析当前页面的 DOM 结构,自动定位目标元素并生成可复用的 CSS 选择器。
前置准备:配置 AI 模型
首次使用前,需要先在「系统设置」中配置 AI 模型。九头虫 RPA 预置了以下 AI 厂商:
| 厂商 | 可选模型 |
|---|---|
| DeepSeek(推荐) | deepseek-chat |
| OpenAI | gpt-5.5、gpt-5.4 |
| Anthropic | claude-opus-4-8、claude-sonnet-4.6 |
gemini-3.1-pro、gemini-3.5-flash | |
| 阿里 | qwen3.7-max、qwen-plus |
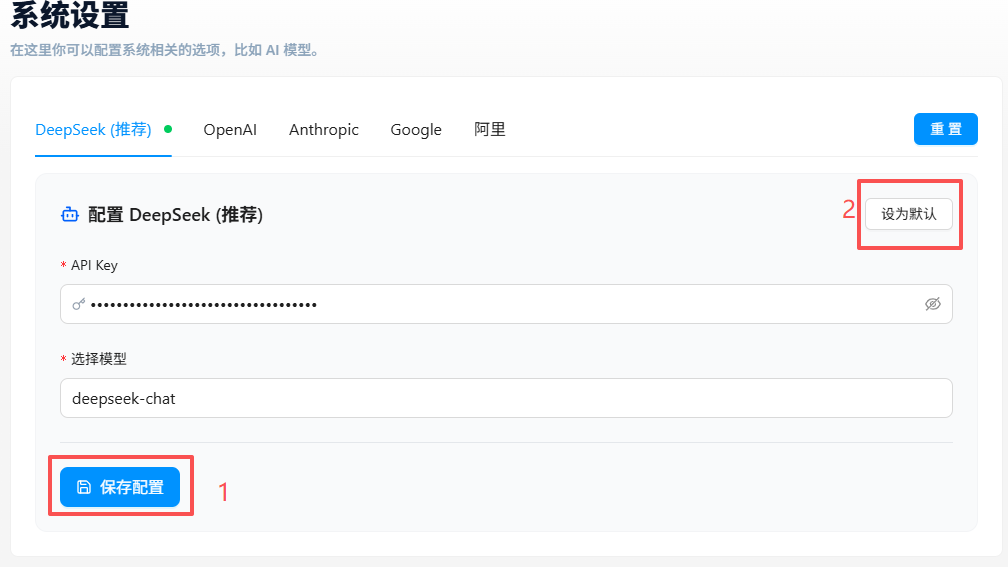
配置步骤:
- 点击插件图标打开九头虫 RPA 面板,切换到「系统设置」页面
- 选择你要使用的 AI 厂商标签页(推荐 DeepSeek,性价比高)
- 填入该厂商的 API Key
- 在「选择模型」下拉框中输入或选择模型名称
- 点击 「设为默认」 激活该配置
- 点击 「保存配置」
获取 API Key:前往对应厂商的开发者平台注册并创建。以 DeepSeek 为例,访问 platform.deepseek.com 即可免费获取。
如何使用
配置完 AI 模型后,在任何节点的「目标元素」配置栏中按以下步骤操作:
- 点击 🤖 机器人图标,从 CSS 模式切换到 AI 自然语言模式
- 在输入框中用大白话描述你要定位的元素,例如:
密码输入框、点击商品名称是 iPhone 15 那一行的编辑按钮 - 点击 ✈️ 发送按钮,AI 会在几秒内分析页面并定位目标
- 寻址成功后,目标元素会被高亮,输入框下方显示自动生成的 CSS 选择器
自动生成的 CSS 选择器可直接使用,也可以在绿色框中手动微调。下次查询同一元素时,系统直接复用缓存的 CSS 选择器,不会再调用 AI。

常用场景与写法
场景一:登录网站
打开了登录页面,填账号密码并登录。
用户名输入框
密码输入框
点击登录按钮
每个描述对应一个节点。一个「输入文字」节点写 用户名输入框,下一个写 密码输入框,最后「点击事件」写 点击登录按钮。
场景二:在列表或表格中定位特定行
你需要在一堆订单中找到特定那行,然后操作它。
点击订单号 20240601001 那行的查看详情按钮
把行的特征说清楚(里面有什么独特的文字),再说要对它做什么。
场景三:填写多字段表单
注册页、信息录入页等,表单里有多个字段。每个节点只定位一个字段,逐个串联。
姓名输入框 → 「输入文字」节点
手机号输入框 → 下一个「输入文字」节点
提交按钮 → 「点击事件」节点
没有标签的输入框可以靠邻居描述:
手机号右边的验证码输入框
场景四:翻页与切换标签
页面有多页或多个 Tab。
点击下一页
切换到"已发货"标签页
场景五:关闭弹窗或提示
弹出广告、确认框、提示条。
关闭弹窗
弹窗里有具体按钮就直接描述那个按钮:
点击弹窗里的取消按钮
场景六:批量采集或勾选
从列表里提取多行,或者勾选多个复选框。
所有商品卡片
勾选状态为"待审核"的所有复选框
场景七:下拉选择
在下拉框中选一项。
在省份下拉框里选择广东省
场景八:按序号定位
一堆相同结构的条目,你只要第 N 个。
点击第三个商品卡片
CSS 选择器(进阶)
如果你熟悉 CSS 选择器,或者需要更精确、更稳定的元素定位,可以直接编写 CSS 选择器。
切换方式
在目标元素输入框中点击 🤖 图标即可在 AI 模式和 CSS 模式之间切换。CSS 模式下输入框提示文字为 输入 CSS 选择器...。
标准 CSS 选择器
如果你已熟悉 CSS 选择器,可直接跳到下一节。以下是自动化中最常用的几类:
| 类型 | 语法 | 示例 | 说明 |
|---|---|---|---|
| 标签选择器 | tag | div | 匹配所有 <div> |
| 类选择器 | .class | .btn-primary | 匹配 class 包含 btn-primary 的元素 |
| ID 选择器 | #id | #submit | 匹配 id 为 submit 的元素 |
| 属性选择器 | [attr=val] | [data-id="123"] | 匹配指定属性值的元素 |
| 后代选择器 | A B | form input | 匹配 <form> 内所有 <input> |
| 子选择器 | A > B | ul > li | 匹配直接子元素 |
| 兄弟选择器 | A + B | .label + input | 匹配紧邻的下一个兄弟 |
| 伪类选择器 | :first-child | li:first-child | 匹配第一个 <li> |
| 通配符 | * | div * | 匹配所有元素 |
自定义伪类
以下伪类为九头虫 RPA 独有,原生浏览器不支持。它们可以像标准伪类一样串联在任意选择器后。
:shadow — Shadow DOM 穿透
穿透 Shadow DOM 边界,将查询上下文切换到元素的 shadowRoot 内部。支持单层穿透和深度递归两种模式。
组件标签:shadow .内部元素
组件标签:shadow(deep) .内部元素
| 语法 | 参数 | 说明 |
|---|---|---|
:shadow | 无 | 单层穿透:切换到当前匹配元素的 ShadowRoot 内部继续查询 |
:shadow(deep) | deep | 深度穿透:递归遍历整个子树(光照 DOM 和 Shadow DOM),收集所有嵌套 ShadowRoot 上下文 |
九头虫 RPA 已内置 attachShadow 拦截补丁,同时支持 mode: 'open' 和 mode: 'closed' 的 ShadowRoot。
示例:假设页面中有如下自定义组件:
<product-card>
#shadow-root (open)
<div class="title">商品名称</div>
<span class="price">¥99.00</span>
<button class="buy-btn">立即购买</button>
</product-card>
/* 单层穿透:穿透 Shadow DOM 获取价格 */
product-card:shadow .price
多层嵌套场景:假设组件存在嵌套 Shadow DOM 结构:
<app-root>
#shadow-root
<product-list>
#shadow-root
<product-card>
#shadow-root
<span class="price">¥99.00</span>
</product-card>
</product-list>
</app-root>
/* 方式一:逐层穿透,每层一个 :shadow */
app-root:shadow product-list:shadow product-card:shadow .price
/* 方式二:使用 :shadow(deep) 一次性穿透所有层级 */
app-root:shadow(deep) .price
:shadow(deep)会递归遍历整棵子树,匹配范围内所有嵌套 ShadowRoot 中的目标元素。如果层级明确,逐层穿透性能更好。
:contains — 按文本内容筛选
筛选 textContent 包含指定字符串的元素。
div:contains('订单号')
a:contains(立即购买)
| 语法 | 参数 | 说明 |
|---|---|---|
:contains('text') | 字符串(必填) | 匹配文本内容包含该字符串的元素,区分大小写 |
示例:假设页面有如下列表:
<ul class="order-list">
<li>订单 #001 — 待发货</li>
<li>订单 #002 — 已发货</li>
<li>订单 #003 — 已发货</li>
<li>订单 #004 — 待发货</li>
</ul>
/* 只匹配文本包含"已发货"的项 */
li:contains('已发货')
/* 可串联其他选择器 */
.order-list li:contains('已发货'):in-viewport
:text — 文本筛选(:contains 别名)
与 :contains 完全一致,两者可互换使用。
span:text('已发货')
:self — 数据采集中的行元素引用
专用于数据采集组件的列提取规则中,用于引用当前行元素自身。不推荐在其他节点中使用。
:self
:self(.highlight)
| 语法 | 参数 | 说明 |
|---|---|---|
:self | 无 | 引用行元素自身,提取其文本内容 |
:self(selector) | CSS 选择器(可选) | 在行元素内部查找匹配参数选择器的后代元素 |
示例:假设用 .product-item 作为行选择器,每行是一个商品卡片:
<div class="product-item">
<span class="title">无线鼠标</span>
<span class="price">¥99</span>
<span class="tag highlight">热卖</span>
</div>
在列提取规则中:
/* 获取行元素自身的文本 → "无线鼠标 ¥99 热卖" */
:self
/* 在行元素内部查找带 .highlight 的后代元素 → "热卖" */
:self(.highlight)
/* 等同于直接在行内查找(推荐写法) */
.tag.highlight
:self在数据采集之外的其他节点中可能有非预期行为,不建议使用。
:col — 表格列匹配
专为 <table> 设计,根据表头列名定位 <td> / <th> 单元格。自动处理 colspan 跨列逻辑。
td:col('商品名称')
td:col('!价格') 严格模式
td:col('姓名, 电话') 多列匹配
| 语法 | 参数 | 说明 |
|---|---|---|
:col('列名') | 列名字符串(必填) | 模糊匹配表头文本 |
:col('!列名') | 以 ! 为前缀 | 严格模式,仅精确匹配表头 |
:col('列A, 列B') | 逗号分隔 | 匹配任意一个指定列 |
示例:假设有如下表格:
<table class="order-table">
<thead>
<tr>
<th>订单号</th>
<th>商品名称</th>
<th>数量</th>
<th>价格</th>
<th>状态</th>
</tr>
</thead>
<tbody>
<tr>
<td>001</td>
<td>无线鼠标</td>
<td>2</td>
<td>¥99</td>
<td>已发货</td>
</tr>
<tr>
<td>002</td>
<td>机械键盘</td>
<td>1</td>
<td>¥499</td>
<td>待发货</td>
</tr>
</tbody>
</table>
/* 定位"商品名称"列的所有单元格 */
td:col('商品名称')
/* 定位"价格"列中文本包含 ¥ 的单元格——实际上就是价格数据 */
td:col('价格')
:in-viewport — 仅匹配可见区域内的元素
筛选当前浏览器视口内可见的元素,不可见元素被排除。
div.item:in-viewport
| 语法 | 参数 | 说明 |
|---|---|---|
:in-viewport | 无 | 仅保留与视口有交集的元素,display:none 或尺寸为零的元素也会被排除 |
使用场景:采集无限滚动列表中的可见项,或只操作用户当前视野中的元素避免触发懒加载。
:not-fetched — 一次性去重
基于内存的去重过滤器,确保同一 DOM 节点只被匹配一次。适合配合元素监控使用,避免重复处理同一元素。
li:not-fetched
li:not-fetched(订单列表)
| 语法 | 参数 | 说明 |
|---|---|---|
:not-fetched | 无(默认命名空间 default) | 元素被匹配后进入内存池,再次匹配时被排除 |
:not-fetched(namespace) | 命名空间字符串(可选) | 不同命名空间的内存池互相独立 |
注意:内存池以 WeakSet 实现,页面关闭后自动清空。:not-fetched 也会排除 offsetHeight 或 offsetWidth 为零的不可见元素。
典型场景:配合「元素监控」触发器,对新出现的 DOM 节点执行一次性操作(如采集数据后不再重复处理):
<!-- 监控容器,列表项会随着时间推移不断增加 -->
<ul class="message-list">
<li data-id="1">新订单 #001,请尽快处理</li>
<li data-id="2">新订单 #002,请尽快处理</li>
<!-- 下一轮轮询时新增了 #003 -->
<li data-id="3">新订单 #003,请尽快处理</li>
</ul>
/* 每次轮询只匹配"还未处理过"的元素 */
.message-list li:not-fetched
/* 多个监控场景使用独立命名空间,互不干扰 */
.message-list li:not-fetched(订单监控)
.error-list li:not-fetched(错误监控)
首次查询匹配 #001 和 #002 并标记为已处理;下一轮轮询时 #001 和 #002 被过滤,只返回新增的 #003。
组合使用
自定义伪类可与标准选择器自由串联:
table.order-table tr:in-viewport td:col('状态'):contains('已完成')
这条选择器的含义:在 class="order-table" 的表格中 → 找到视口可见的行 → 定位"状态"列的单元格 → 仅保留文本包含"已完成"的。
验证选择器
自定义伪类和 AI 自然语言选择器均无法在浏览器原生 API(如 querySelectorAll)中生效,也无法在开发者工具 Elements 面板中搜索验证。推荐在以下组件的配置面板中测试:
- CSS 模式:填入选择器后,点击字段右下角的 👁 预览按钮即可实时查看匹配到的元素列表。
- AI 模式:输入描述后点击 ✈️ 发送按钮,AI 寻址成功后会自动显示生成的 CSS 选择器及匹配结果。
- 两种方式都无需运行流程即可验证。
常见问题
在浏览器 Console 中用 querySelectorAll 测试不生效
现象:在 Console 中使用 document.querySelectorAll('div:contains('订单')') 报语法错误或无匹配。AI 模式生成的 CSS 选择器同样依赖自定义伪类引擎,原生 API 也无法验证。
原因:自定义伪类是九头虫 RPA 的扩展语法,浏览器原生 API 无法识别。
解决:在「数据采集」或「设置变量」节点的配置面板中填入选择器进行测试,配置面板内置了自定义伪类引擎,会实时展示匹配结果。
AI 自然语言模式找不到目标元素
现象:描述了一个元素,但 AI 返回错误或匹配不到元素。
原因:常见原因是 AI 模型未配置、描述不够具体、或页面 DOM 结构与描述差异较大(如动态渲染的弹窗)。
解决:
- 检查「系统设置」中是否已配置 AI 模型(API Key 和模型名称);
- 让描述更具体,加入元素的文本内容、标签类型、或空间位置信息(参考上方的示例);
- 如果 AI 返回了元素但不符合预期,可以切换到 CSS 模式,在自动生成的 CSS 选择器基础上手动微调。
:shadow 穿透后找不到元素
现象:使用了 :shadow,但后续的选择器报"未找到元素"。
原因::shadow 后的选择器路径不匹配实际 DOM 结构,或 :shadow 层级不够(嵌套 Shadow DOM 中某一层未穿透)。
解决:在开发者工具中展开 Shadow DOM 树,逐层确认实际结构,确保每一层 Shadow DOM 边界都有对应的 :shadow(或直接使用 :shadow(deep) 一次性穿透所有层级)。